
Zero-Shot Text Classification & Evaluation
Published:
Recently, zero-shot text classification attracted a huge interest due to its simplicity. In this post, we will see how to use zero-shot text classification with any labels and explain the background model. Then, we will evaluate its performance by human annotated datasets in sentiment analysis, news categorization, and emotion classification.
Zero-Shot Text Classification
In zero-shot text classification, the model can classify any text between given labels without any prior data.
With zero-shot text classification, it is possible to perform:
- Sentiment analysis
- News categorization
- Emotion analysis
Background
Actually, the latest implementations of zero-shot text classification born out of a very simple but brilliant idea. There is a field called Natural Language Inference (NLI) in NLP. This field investigates whether a hypothesis is true (entailment), false (contradiction), or undetermined (neutral) for a given premise.
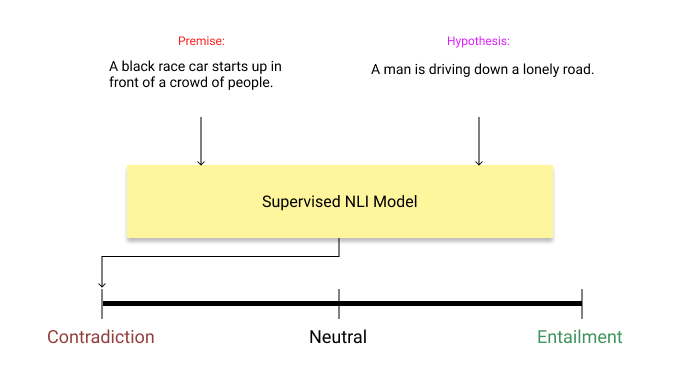 *Supervised NLI System*
*Supervised NLI System* Now, let’s assume our text is “I love this movie.” and we want to predict the sentiment of the text between candidate labels of positive and negative. We give these two hypothesis-premise pairs to already trained NLI model and check the results.
Premise: I love this movie.
Hypothesis-1: This example is positive.Premise: I love this movie.
Hypothesis-2: This example is negative.
Basically, it creates hypothesis template of “this example is …” for each class to predict the class of the premise. If the inference is entailment, it means that the premise belongs to that class. In this case, it is positive.
Code
Thanks to HuggingFace, it can be easily used through the pipeline module.
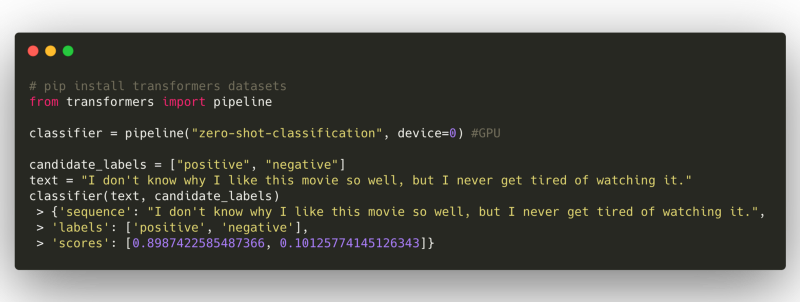 *Initializing the classifier with an example of sentiment analysis*
*Initializing the classifier with an example of sentiment analysis* In the first example, we initialize the classifier from transformers pipeline and then give an example from IMDB dataset. You can see that the classifier produces scores for each label. In the first example, it predicts the sentiment of the text as positive, correctly.
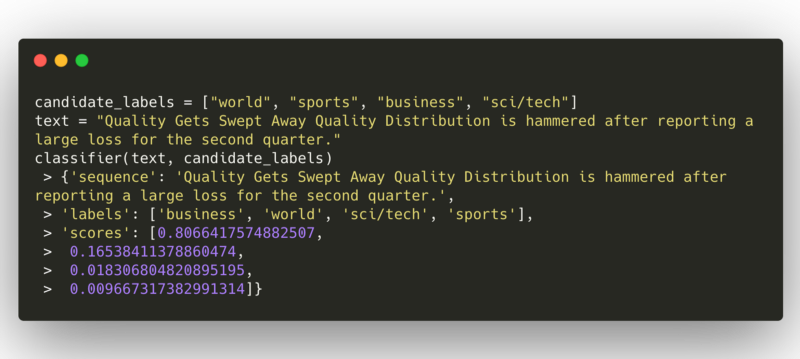 *Example of news categorization*
*Example of news categorization* Our second example is for news categorization from AG News dataset. It correctly predicts the news in business category.
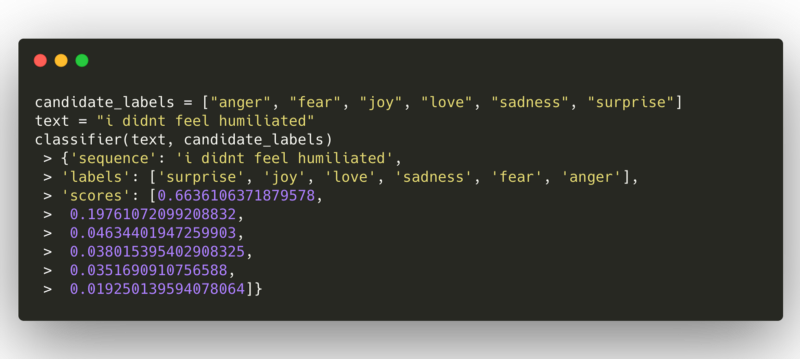 *Example of emotion classification*
*Example of emotion classification* In our last example, we investigated an example from Emotion dataset. Zero-shot classification model predicts emotion of the sentence “i didnt feel humiliated” as surprise, however gold label is sadness.
Evaluation
Zero-shot classification looks promising in these examples. However, its performance should be evaluated with correct measurements by using already labeled examples.
 *Cherry-picking??? Photo by Andriyko Podilnyk on Unsplash*
*Cherry-picking??? Photo by Andriyko Podilnyk on Unsplash* By using the latest dataset library of HuggingFace, we can easily evaluate its performance on several datasets.
- IMDB dataset: sentiment analysis
Classes: positive, negative - AG News dataset: news categorization
Classes: world, sports, business, sci/tech - Emotion dataset: emotion classification
Classes: anger, fear, joy, love, sadness, surprise
Let’s compare our zero-shot text classification model with the state-of-the-art models and random pick in micro-average F1.
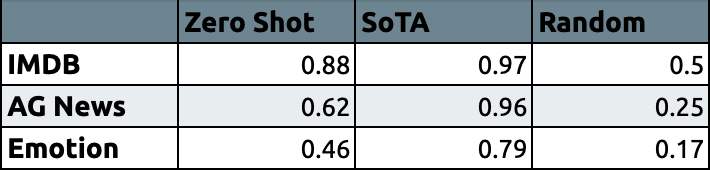 *Micro-average F1 in different datasets*
*Micro-average F1 in different datasets* For more details about initializing zero-shot classification pipeline and evaluation code, check out this well-prepared Colab Notebook.
Conclusion
We can see that zero-shot text classification performs significant results in sentiment analysis and news categorization. The performance in the emotion classification with 6 class is rather poor. I believe that it might be due to the similarity between classes. It is a very hard task to make distinction between joy, love, and surprise classes without any prior data.
Performance of zero-shot classification is lower than supervised models for each task as expected. Even so, it’s worth trying if you don’t have any data for a specific classification problem!