
Understand Tweets Better with BERT Sentiment Analysis
Published:
Sentiment Analysis
Sentiment Analysis is one of the key topics in NLP to understand the public opinion about any brand, celebrity, or politician. Thanks to pretrained BERT models, we can train simple yet powerful models. In this study, we will train a feedforward neural network in Keras with features extracted from Turkish BERT for Turkish tweets.
Dataset
In this study, we will use BOUN Twitter Data (2018) which have 8000 of Turkish tweets with 3 classes: positive, neutral, negative. This dataset is annotated by different judges.
Also, this dataset is imbalanced: 52% is neutral, 30% is positive, 18% is negative. We will take care of this problem.
Code
Complete version of this code and the datasets can be reached in my github repo.
1. Importing libraries and paths
Let’s start with importing required libraries:
import json
import random
import warnings
from datetime import datetime
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
from keras.callbacks import EarlyStopping
from keras.layers import Dense, Dropout
from keras.models import Sequential
from keras.optimizers import Adagrad
from sklearn.decomposition import PCA
from sklearn.metrics import classification_report, f1_score
from sklearn.utils import class_weight
from tqdm import tqdm
from transformers import AutoModel, AutoTokenizerSet paths of the dataset, path of tweet jsons for analysis, and the device.
Using CPU for the training is sufficient but feature extraction with BERT can take some time.
train_path = 'Boun Twitter Data/train.json'
val_path = 'Boun Twitter Data/validation.json'
test_path = 'Boun Twitter Data/test.json'
cappy_path = 'Other Data/cappy.json'
bege_path = 'Other Data/berkcan.json'
netflix_path = 'Other Data/netflix.json'
device = 'cuda' #set to cpu if you don't have gpu2. Filtering and Feature Extraction with BERT
Simple filter function for links and mentions.
def filter(text):
final_text = ''
for word in text.split():
if word.startswith('@'):
continue
elif word[-3:] in ['com', 'org']:
continue
elif word.startswith('pic') or word.startswith('http') or word.startswith('www'):
continue
else:
final_text += word+' '
return final_textNow, it is the BERT time. We are using Turkish tweets, so we use Turkish BERT. If you want to train a model for another language, check out community models of huggingface. If you cannot see a model for that language, you can use multilingual BERT.
This feature_extraction method:
- Takes a sentence.
- Filter it with our simple filter method.
- Tokenize it with Bert Tokenizer.
- Produce a vector with the length of 768 to represent the sentence.
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-turkish-128k-uncased")
bert = AutoModel.from_pretrained("dbmdz/bert-base-turkish-128k-uncased").to(device)
def feature_extraction(text):
x = tokenizer.encode(filter(text))
with torch.no_grad():
x, _ = bert(torch.stack([torch.tensor(x)]).to(device))
return list(x[0][0].cpu().numpy())Let’s load our dataset and process through our feature extraction method.
data_prep function takes a dataset portion(train/val/test) and extract features for each sentence. Also, produces one hot encodings of sentiments ([1, 0, 0] for negative, [0, 1, 0] for neutral, [0, 0, 1] for positive)
mapping = {'negative':0, 'neutral':1, 'positive':2}
def data_prep(dataset):
X = []
y = []
for element in tqdm(dataset):
X.append(feature_extraction(element['sentence']))
y_val = np.zeros(3)
y_val[mapping[element['value']]] = 1
y.append(y_val)
return np.array(X), np.array(y)
with open(train_path, 'r') as f:
train = json.load(f)
with open(val_path, 'r') as f:
val = json.load(f)
with open(test_path, 'r') as f:
test = json.load(f)
X_train, y_train = data_prep(train)
X_val, y_val = data_prep(val)
X_test, y_test = data_prep(test)3. Training a Model
Now, it is the BEST part. We are starting to train a model. Let’s define the model first.
- We use class_weights to take care of our imbalanced dataset(To prevent tendency of predicting neutral most of the time due to its high frequency).
- Dropout layers for regularization.
- Softmax activation function for final layer and tanh for others.
- Adagrad optimizer.
- Categorical crossentropy loss function which is suited for multiclass classification.
class_weights = class_weight.compute_class_weight('balanced', np.unique(np.argmax(y_train, 1)), np.argmax(y_train, 1))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=50)
model = Sequential()
model.add(Dense(512, activation='tanh', input_shape=(768,)))
model.add(Dropout(0.5))
model.add(Dense(128, activation='tanh'))
model.add(Dropout(0.5))
model.add(Dense(32, activation='tanh'))
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=Adagrad(),
metrics=['accuracy'])Now, let’s start the training and check out our scores in the test set.
history = model.fit(np.array(X_train), np.array(y_train),
batch_size=64,
epochs=500,
verbose=1,
validation_data=(X_val, y_val),
class_weight=class_weights,
callbacks = [es])
y_true, y_pred = np.argmax(y_test, 1), np.argmax(model.predict(X_test), 1)
print(classification_report(y_true, y_pred, digits=3))4. Results
Results of the test set:
| Data | Precision | Recall | F1-Score |
|---|---|---|---|
| Positive | 0.529 | 0.682 | 0.596 |
| Neutral | 0.847 | 0.696 | 0.764 |
| Negative | 0.597 | 0.684 | 0.638 |
| Average | 0.658 | 0.688 | 0.666 |
We can use average recall for our final score which is used in Semeval 2017 - Task 4. Also, average is macro average of scores in here. So, we don’t take the number of tweets in each class into account while taking average.
The results might be a little bit different(less than 1%) in each time because we shuffle training data in model.fit() in each epoch and it generates randomness to the results.
5. Analyze
Now we will analyze real tweets by our model!
5.1. Cappy
Our first suspect is Cappy. Lately, I have seen tweets about Cappy juice in Turkey which have unidentified objects in it. People were talking about this and I want to see the effect. The ugly tweets:

Tweet 1

Tweet 2
First, tweets are collected by using TweetScraper with Cappy keyword and Turkish language and saved to cappy.json file. Then, our model predicted sentiments of the tweets and remove 1 to map values between (-1,1).
After that we simply print figure with moving average to see effect of these tweets.
cappy_df = pd.read_json(cappy_path).query('is_retweet==False').drop_duplicates(['text'])[['text', 'datetime']]
cappy_df['value'] = 0
#-1 negative 0 neutral 1 positive
for idx, row in tqdm(cappy_df.iterrows()):
X = feature_extraction(row['text'])
cappy_df.at[idx, 'value'] = np.argmax(model.predict(np.array(X).reshape(1, -1)))-1
incident1 = datetime.strptime('2020-01-28 15:20:00', '%Y-%m-%d %H:%M:%S')
incident2 = datetime.strptime('2020-04-07 19:34:00', '%Y-%m-%d %H:%M:%S')
dates = np.array(cappy_df['datetime'])
indices = np.argsort(dates)[5300:] # it is set 5300 to see newest tweets better in the figure.
window = 750
dates = dates[indices][window:]
values = np.array(cappy_df['value'])[indices]
windows = pd.Series(values).rolling(window)
moving_averages = windows.mean()[window:]
plt.figure(figsize=(12,6))
plt.plot(dates, moving_averages, color='blue', label='Average Sentiment')
plt.axvline(incident1, 0, 1, label='Date of the First Incident', color='red', alpha=0.5)
plt.axvline(incident2, 0, 1, label='Date of the Second Incident', color='red', alpha=0.7)
plt.title('Analysis of Turkish Tweets about Cappy')
plt.xlabel('Date')
plt.ylabel('Sentiment Score')
plt.legend();The results are beautiful! Big drops due to popularity of these two tweets.

Scores
5.2 Netflix
Lately, big discussion about Netflix in Twitter occured after their new Turkish series with LGBT content.

Tweet
The drop in sentiment is clearly visible in here too.

Scores
5.3 Berkcan Guven (Youtuber)
Our last suspect is one of the most famous youtubers in Turkey, Berkcan Guven. Berkcan Guven released a debatable video with underage celebrity. He removed the video 7 hours after uploading but 700k people watched it already. Let’s see the effect of this in Twitter.

Video
We also see week-long drop in sentiments about Berkcan Guven after the video.
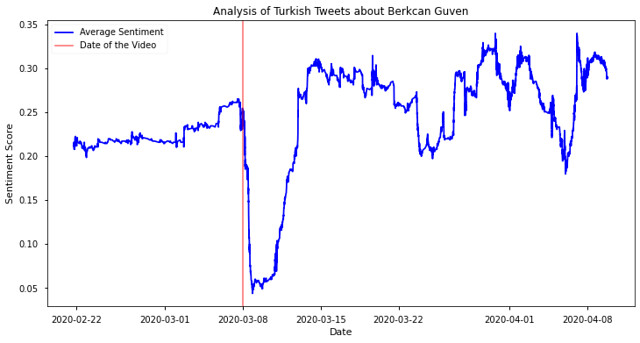
Scores
Conclusion
We trained a feedforward neural network with BERT features for sentiment analysis task. We also used this model to analyze popular topics in Twitter and we captured correlation between incidents and Twitter sentiments.
For the complete notebook and the datasets, check out my github repo.